
计算机组成 5
Chapter 5 Exploiting Memory Hierarchy
- Memory Technologies (介绍存储类型)
- Memory Hierarchy Introduction (层次化概念)
- The basics of Cache (高速缓存介绍)
- Measuring and improving cache performance (高速缓存性能提升)
- Dependable Memory Hierarchy ()
- Virtual Machines (虚拟机)
- Virtual Memory (虚拟内存)
- A common Framework for Memory Hierarchy (计算机通常层次化内存结构)
- Using FSM to Control a simple Cache (用状态机控制缓存)
1. Memory Technologies
Review:
SRAM:
- use CMOS as a basic element.
- N型(没有小圆圈)给1是导通状态
- P型(有圆圈)给0是导通状态
vcc接p,gnd接n,构成一个非门。
- 两个CMOS反相器构成1bit单元,再加上写入读出CMOS构成
- use CMOS as a basic element.
DRAM:
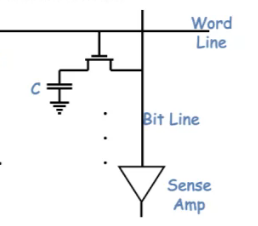
- 构造:使用电容(一个管子),体积小,但读的速度比SRAM慢,需要不断刷新
- Write: 给bit line充上1/0(本身既不是1也不是0),给word line设置成1
- Read: 先给bit line pre-charge 一下,word line设置成1,bit line 会变高/低,sense amp来读取是1还是0
- 通常使用阵列,寻址:先行后列的方式,分时复用确定地址(减少引脚数量)。(也是比较慢的原因)
- DRAM 是访问一整行
- Burst Mode 一下子读出一大堆相连的数据,这样尽可能减少读取所需时间
- DDR SDRAM (双倍数据率同步动态随机存取存储器)上升沿下降沿都利用起来,比DRAM快一倍
- QDR 输入输出分开了,可以同时进行读写,速度又提升了一倍
- 构造:使用电容(一个管子),体积小,但读的速度比SRAM慢,需要不断刷新
Flash Storage 闪存
- 比硬盘100/1000倍快,固态硬盘也是这玩意做的,还可以做的更小、稳定
Disk Storage 磁盘
- 磁道、读写磁头、……
总结:大的存储器不快,快的存储器不大(贵)
2. Memory Hierarchy Introduction
程序总是在一些时刻访问一小部分的内容:
Temporal Locality
- 时间局部性原理:最近被访问的内容大概率被再次访问
Spatial Locality
- 空间局部性原理:刚被访问过的内容旁边的内容大概率被访问
Taking Advantage of Locality
- 所有东西都存在disk上面
- 把最常访问的东西从disk存到DRAM上面(Main Memory)
- 把最近访问的内容放到更小的SRAM上面(Cache, 和CPU高度相关)
Some Important Items
- Block: 数据复制的基本单位
- Hit “命中”,要访问的内容就在 upper level 的存储单元里
- Hit Time 命中了要消耗的时间(访问upper level)
- Hit Ratio
- Miss “缺失”,会把这部分内容从 lower level 里提取出来
- Miss Penalty 缺失造成的时间开销
- Miss Ratio = 1 - Hit Ratio
Exploiting Memory Hierarchy
从上到下:
- Register
- L1- Cache (on chip)
- L2- Cache (SRAM)
- Main Memory (DRAM)
- Disk, Tape, …
3. The basics of Cache
two issues:
1. How to know if a data item is in the cache?
direct-mapping algorithm: 怎么放?取模!
DRAM的数据放到SRAM中,把DRAM的地址取模,模上8(Cache大小),余数就是其在对应的位置。
实际上就是取高位。相同低位的地址的内容共享一块cache的block。
也意味着,00001,01001,10001,11001,不可能同时存在于Cache中。
Tag and Valid Bits:
- Tag: Cache里存的不只是数据,也存放了高位地址(低位地址是自身的index)
- Valid Bits: 还放了有效位,表明其是不是真正存着东西
- 实际上一个block: Valid bit, Tag, Data
Cache的直接映射策略:
- Cache实际存放【Valid】(【Dirty】)【Tag】【Data】
- 32/64位地址,如果是按照字节寻址,实际被映射为【Tag】【Cache Index】【Word Offset】【Byte Offset】长度加一起为64,Byte Offset一般为“Word有几个byte”,Word Offset一般为“Cache的一个block(最小单元)有几个word”。
- 其中【Cache Index】长度取决于Cache被分为几个block,取完log
- 其中【Word Offset】+【Byte Offset】长度取决于cache的一个block有几个Byte,也就是与【Data】长度有关,log([Data])-3
- 其中【Tag】长度取决于以上两点
2. If it is, how do we find it?
Memory block address: Tag+index+offset of the block.
3. Handling Cache reads hit and Misses
Hit 就好了,如果miss了
Instruction miss:(READ)
CPU停下来,等整个block传送到Cache,之后再重启CPU,hit,执行程序
- 将原有PC(加4之前miss那条) 给memory
- 等待memory读出来
- Tag和valid bit设置,value设置
- 重启CPU
Data miss:(READ/WRITE)
Write Hit:
- WRITE BACK: 原先的data已经在Cache里面了,只将数据写入data cache里面。(现在cache里的数据和dram数据不一样了,会有inconsistent,但是fast)
- WRITE THROUGH: 把数据写在Cache和Dram之中,会慢
Write Miss:
- 把整个block写入缓存,之后写入word
Deep conception in Cache:
四个主要问题:
- Block Placement (还有其他策略)
- Block Identification (tag/block)
- Block Replacement (random,lru,fifo)
- Write Strategy (writeback/through)
Q1: BLock Placement 块放置的方式
Direct mapping
讲过了
Fully Associative
Block 能在Cache里面任何位置
Set Associative
Block 能去取模之后的几个位置之一(set组)
Q2: Block Identification 块的定位
Tag+index+offset。如何定位的?
先是看mem的index,定位到cache的位置
再检查valid位和tag,看看这个cache对应的是否是mem的地址
最后在offset找到data的位置
Q3: Block Replacement 块替换策略
内存块替换:
直接映射不涉及内存块替换(一个内存只对应一个地址,如果cache冲突就只能替换掉)
组关联和全关联,组关联一个内存地址对应一个set的大小数量个地址,全关联对应整个cache大小数量个地址
Random Replacement
好实现
Least-Recently Used (LRU)
需要额外的位来跟踪accesses
First in First out (FIFO)
先进的先出
Q4: Write Strategy 写策略
write through (改变data之后从cache和mem都写入,只需要valid bit,有掉电保护但是慢)和 write back (只写入cache,一次性地写回mem,额外需要一个dirty bit)
write through advance read misses 不会导致写入,好实现,对多核一个主存的cpu更友好(consistent)
write back advance 对mem带宽要求低
Write Stall
write through 的时候CPU一定要等的
write buffer:

write buffer是一小块cache,作为写入的缓冲区,减少写入过程等待memory写消耗时间的stall
Write Misses
write allocate:把要改的内存先加载到cache,再找时间写入到mem(使用write back)
write around:不加载到cache直接写入到mem(使用write through)
Performance in Four-way interleaved memory
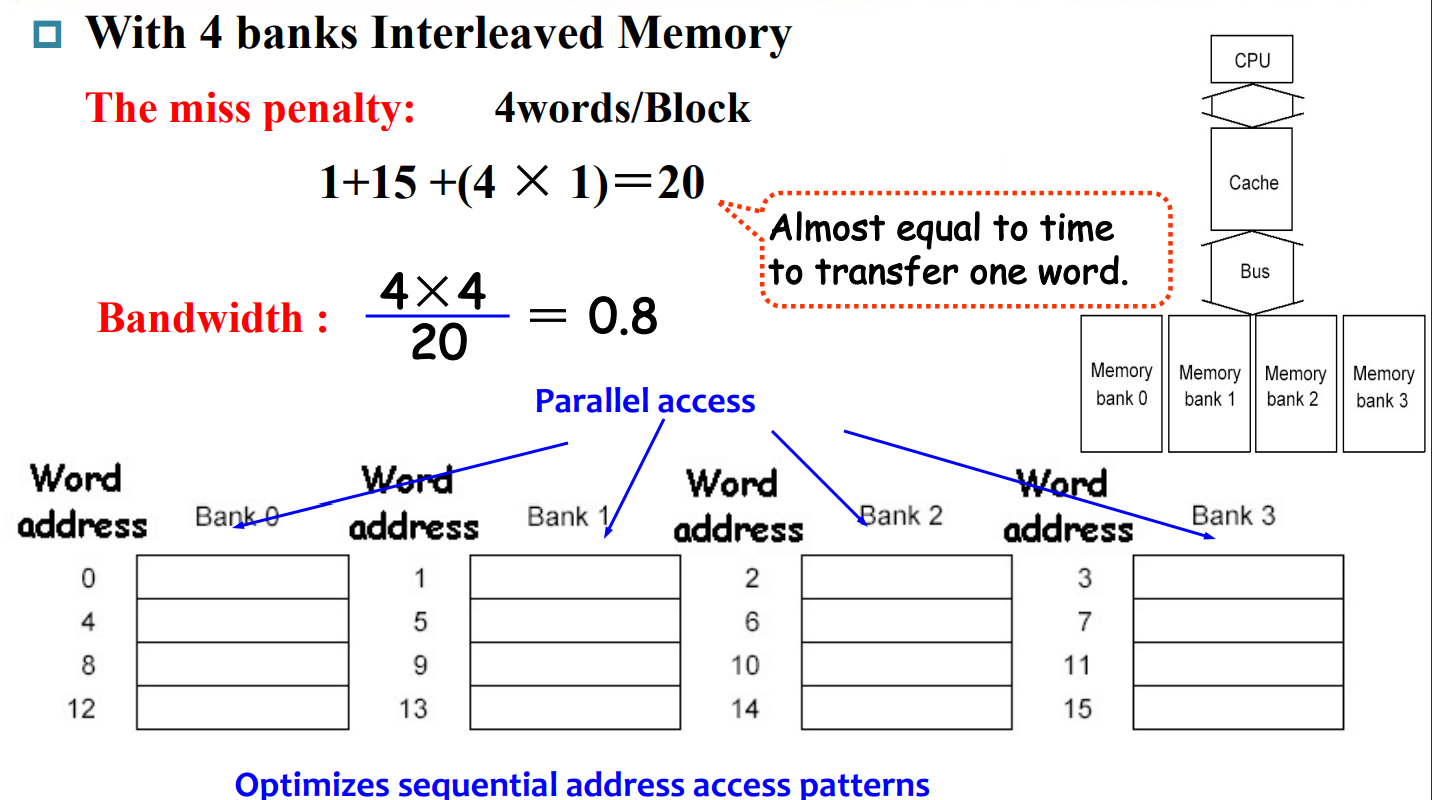
将Memory根据word分成几个部分,向cache传输资源时“分时复用”,减少memory miss的代价
bus短(比如说1个word)的话,每个block取回来要分四次上传
bus长很好,但是成本比较高
Interleaved的方法做到“分时复用”,间隔上传,减少成本增大带宽。
4 Measuring and improving cache performance

Average Memory Access time= hit time + miss time
= hit rate * cache time + miss rate * memory time
Measuring cache performance
*CPU time = (CPU执行周期+ memory stall的周期)cycle time
Read-Stall:
time=$\frac{read}{program}\times miss\ rate \times miss\ penalty$
miss penalty一般都被转算成需要额外多少个周期了
Write-Stall:
- write through 的 penalty 近似为0,所以stall的时间主要看mem写入时间
- write back 大多数这种情况下,read 和write的penalty都一样的,都是从memory从block中取回所需要的时间
计算还是很好算的
发现限制CPUtime的主要还是在于cache的penalty time,解决方法:
- 设计cache的block placement减少replace 的次数
- 多级缓存,每级缓存miss都有一个概率,降低到memory的miss的概率
7 Virtual Memory
Main Memory act as a Cache for the secondary storage (like disk storage)
将内存的地址映射到disk的地址。虽然虚拟内存是连续的,但是所映射的物理内存空间未必连续。
虚拟内存的block——Page:
虚拟地址高位:Virtual Page Number,低位:Page offset
虚拟内存的miss:Page Fault
需要从disk读取内容到memory
miss penalty很大,因为一个page就很大
减少page fault的次数,需要替换策略(LRU
使用write back,因为每次写入disk的代价太高
可以在软件层实现该过程(OS)
需要Page Table,储存 虚拟内存(CPU地址)到物理内存的映射。
这个物理内存(翻译成实际内存应该更好一点)可能在mem中也可能在disk中
如果调用的在disk中,就要尽量把它提出来替换到mem里面,然后更新Page Table的映射
所以说虚拟内存实际上扩大了内存的容量,用一部分disk内容当作实际内存了
每个程序都会有一个page table
OS中CPU进程之间相互切换,就是包含page table切换的过程

顺序:
得到一个地址,检查TLB试图找出物理内存,没有就取PageTable找,再没有就是Page Fault,不在mem中也肯定不在cache中
如果TLB没找到,PageTable找到了,就按照得到的物理内存搜索mem,这个地址一定在mem中,但未必在cache中
如果TLB找到了,PageTable一定也能找到,去mem中找,有可能在cache中
TLB是Page Table的缓存,PageTable miss了TLB一定miss,反之未必
Page Table
- Miss time = Hit time + miss rate * miss penalty
 wechat
wechat alipay
alipay
