
计算机组成 4
Chapter 4 Processor
computer CPU:
- control unit
- data path
Outline
Introduction
Logic Design Conventions
Building a Data path
A Simple Implementation Scheme
Introduction:
The Data path
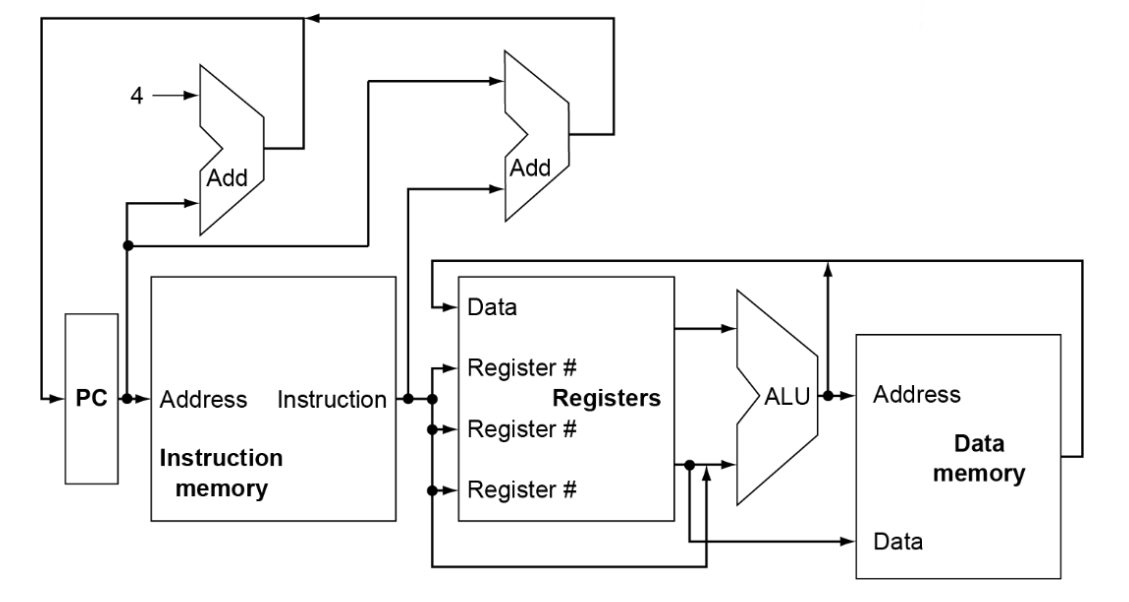
The Control unit
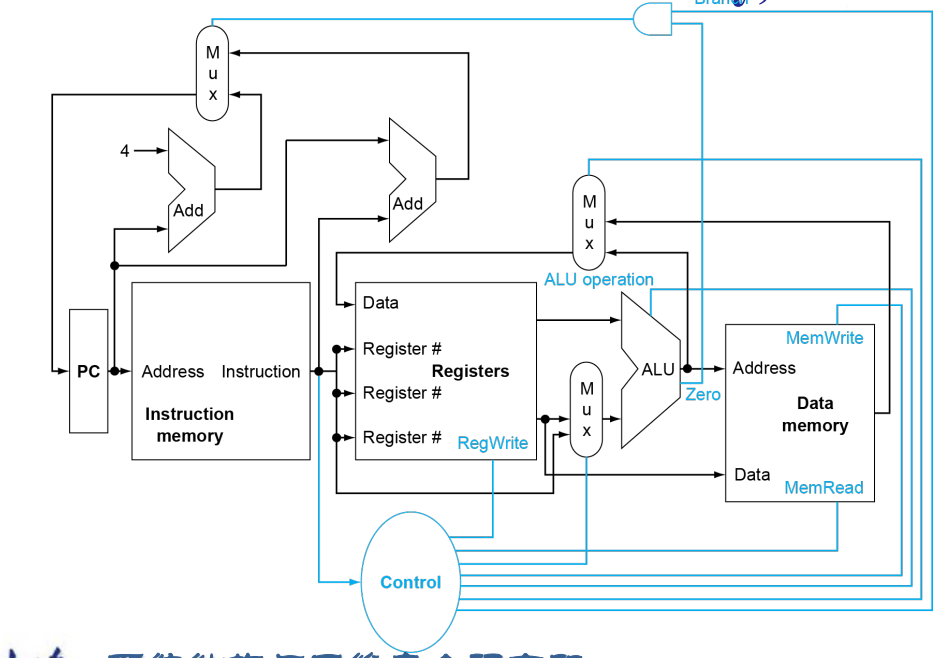
Instruction execution of instruction
Fetch
- take instruction from the instruction memory
- modify pc to point the next instruction
Instruction decoding
executive control
memory access
Write to memory
Update PC
Hazards
Structure hazards
指令在不同步骤执行的过程中访问硬件冲突
所以RISCV将指令和数据分开存储
还有一种:WB和ID之间Structure hazard,处理方式是WB执行周期的前半段,ID执行周期的后半段
Data hazards
下一条指令的寄存器的值依赖于上一次计算得出的结果
同为计算指令,可以从上一步ALU直接连到下一步的ALU
但是在ld指令后接sub计算指令,需要在上一步mem步骤后执行ex。
一种处理方法是插入bubble指令,等上一步的结果出来
另一种优化思路是调整指令顺序 Code Scheduling to Avoid Stalls
Control hazards
取下一条指令依赖于上一条的结果。也就是是否跳转的问题
处理方式:分支预测 Branch Prediction
静态分支预测:默认跳转或者默认不跳转
动态分支预测:跳不跳转取决于上一次是否成功跳转
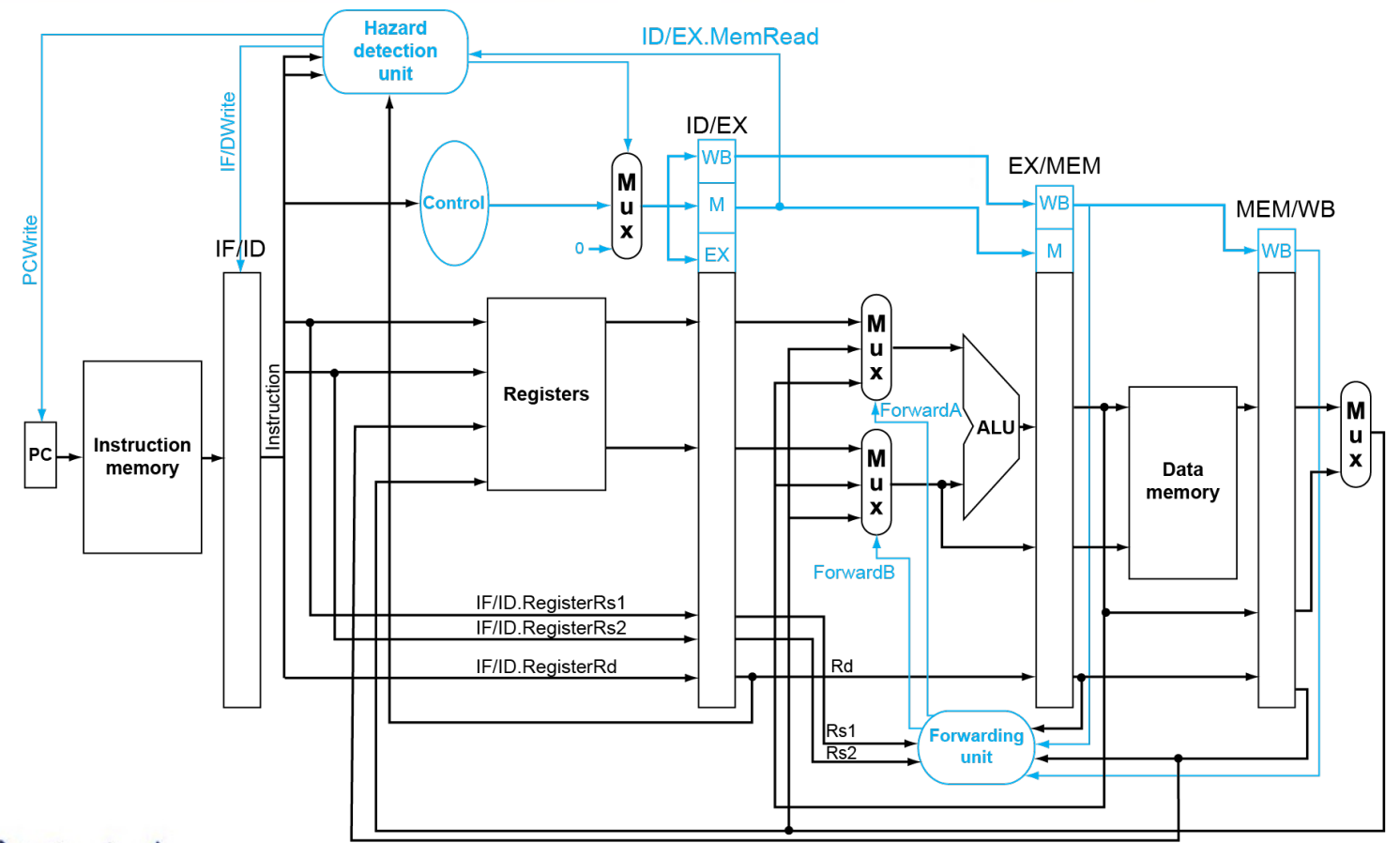
Pipeline Operation
We need registers between stages to store the data of the previous cycle.
Forwarding
条件:
1a. EX/MEM.RegisterRd = ID/EX.RegisterRs1 |
且EX/MEM.RegisterRd 和 MEM/WB.RegisterRd必须是有写入(WB)操作
其次,寄存器不能是x0
Double Data Hazard
使用较近的作为forward的来源,处理设置一个优先级
Load-use Hazard
condition
ID/EX.MemRead and |
由于下一步需要ID上一步WB的结果(如果是pipeline register,其实是上一步mem的结果)最差也要差一个stage,所以需要bubble。
具体实现需要提前detect。
发现后具体操作:
EX MEM WB控制信号置为0,然后不能让PC正常+4、IF/ID寄存器变化,相当于这个instruction IF/ID了两个stage(Fetch了两遍)
总体上看stall降低性能,最好在编译器阶段避免code出现load use hazard
Branch Hazards
正常来讲会提前执行3条指令,如果未命中会bubble3条指令(做错没关系因为不会到WB那一步)
一种优化是把beq结果在ID步骤提前得出来,这样未命中只会bubble一条指令。但是对性能提升并不够。
Dynamic Branch Prediction 动态分支预测
记下来上一步的分支结果作为下一次预测的结果。
但是还有的问题是多重for循环,这样采取 2-Bit Predictor ,又一次的容错率。只有连续两次都预测错误才会更改预测数据。
Branch target buffer 分支目标缓存
就算预测对了,计算目标地址也会有一个时钟周期的penalty
解决方案是设计一个target address cache,对应Pc地址指向目标地址。结果是可以从IF步骤就可以根据之前的Predictor,得出接下来的目标地址,于是就可以在下一周期的IF步骤使用这个预测地址的PC。
Exceptions and Interrupts 异常和中断
Exception来自CPU,中断源自IO
Handling Exceptions 解决异常
要跳到目标异常对应的地址,但是执行完要保证回到原来位置
所以把当前PC存储到 Supervisor Exception Program Counter(SEPC)
将中断信息放在Supervisor Exception Cause Register(SCAUSE)里
之后跳到固定地址执行处理程序,ld SCAUSE处理中断
中断处理:
- 某个指令出问题(exception保存PC,interrupt就保存PC+4)
- 执行完前面的指令,flush掉出错的以及出错后面的寄存器
- 之后:
- 跳到一个固定位置handler,开始处理
- 跳到中断向量表中,再根据表跳到相应处理位置
“Precise” exceptions
多个异常同时发生,先处理最开始的指令触发的异常
Multiple Issue 多发
ILP 指令级别并行 Instruction-Level Parallelism
同时执行多条指令
Static multiple issue
编译器处理,将可以多发的指令放在一起,并且调整指令检测并避免hazard
Dynamic multiple issue
CPU自己处理指令,排序,处理竞争
Dual Issue: 两条ld/sd 和 alu运算指令同时进行
让Dual Issue 效率更高的方法:
LOOP unrolling 循环展开
就是把循环体展开几层
费存储空间但是IPC可能会更高(Instruction per cycle)
Register Renaming
需要注意的是:展开要把内置寄存器renaming防止冲突
Speculation 投机
不考:不确定就确定地做下去,要是错了再改
也分成static和dynamic两种scheduling
4.9 Exception
privilege:
| Level | Encoding | Name | Abbreviation | |
|---|---|---|---|---|
| 0 | 00 | User/Application | U | 用户模式 |
| 1 | 01 | Supervisor | S | 监督模式(操作系统) |
| 2 | 10 | Reserved | 保留 | |
| 3 | 11 | Machine | M | 机器模式(最高权限,必须支持的模式) |
最基本的只支持M模式,最简单的嵌入式程序
USM模式,Unix-like
UM模式 ,安全的嵌入式程序
中断都是在M模式下执行。
CSR寄存器(了解)
有特定的指令
| Name | Function | Description |
|---|---|---|
| MRET | PC<=MEPC | 机器模式下回到用户模式 |
| e call | MEPC<=PC of the called instruction | 用户模式下调用 |
| e break | MEPC<=PC of the e break | 程序断点 |
几个常用的寄存器
| CSR | privilege | Abbreviation | Name | Description |
|---|---|---|---|---|
| 0x300 | MRW | mstatus |
中断使能寄存器,给不同的模式行使中断的权限 | |
| 0x305 | MRW | mtvec |
中断向量表地址的base。MODE=direct模式,所有的中断设pc为BASE。MODE=vector模式,跳转到$BASE+4\times cause$ | |
| 0x341 | MRW | mepc |
保存pc的值。如果是异常:$mepc\leftarrow pc$.中断: $mepc\leftarrow pc+4$ | |
| 0x342 | MRW | mcause |
最高位表示是中断还是异常,剩下的位表示触发中断或者异常的原因 |
 wechat
wechat alipay
alipay
